
Estamos en medio de un auge de la IA.
La IA está en todas partes. Si usó la autocorrección al escribir o enviar mensajes de texto, buscó respuestas en línea usando un motor de búsqueda o usó software de reconocimiento facial para desbloquear su teléfono, entonces ha estado usando IA. La tecnología es omnipresente y está evolucionando a una velocidad vertiginosa.
El uso de la IA en el ámbito sanitario data de hace más de 50 años. Si bien los chatbots como ChatGPT han acaparado la atención recientemente, el primer chatbot médico, llamado ELIZAfue desarrollado en la década de 1960. Pronto siguieron otras herramientas de IA: en la década de 1970, un sistema denominado MYCIN fue diseñado para diagnosticar infecciones bacterianas y recomendar un tratamiento antibiótico adecuado, y en la década de 1990, el Sistema ImageChecker fue desarrollado y se convirtió en el primer sistema de IA de imágenes aprobado por la FDA para la detección asistida por computadora de mamografías de detección. Hoy en día, la IA médica continúa avanzando, con capacidades científicas básicas como predecir la forma 3D de cualquier proteína hasta aplicaciones clínicas como ayudar con procedimientos quirúrgicos.
Uno de los primeros campos médicos en implementar ampliamente la IA fue la radiología, donde se utilizan algoritmos de aprendizaje automático para ayudar a interpretar imágenes médicas. Las imágenes médicas contienen enormes cantidades de datos. Estos datos se pueden extraer en busca de patrones y asociaciones que puedan facilitar la detección de enfermedades, predecir resultados clínicos e impulsar decisiones terapéuticas. Pero el desarrollo de algoritmos para ayudar con estas tareas aún no se ha racionalizado por completo y quedan muchas preguntas: ¿Cómo se regulan los algoritmos? ¿Están seguros los datos? ¿Los modelos se desarrollan sin sesgos?
Recientemente hablamos con Maryellen Giger, Ph.D., profesora de radiología en la Universidad de Chicago e investigadora de contacto principal del Centro de recursos de datos e imágenes médicas (MIDRC), un depósito de datos financiado por NIBIB que se desarrolló durante la pandemia de COVID-19. Ella nos habló de la creación de MIDRCcómo se pueden utilizar el repositorio de imágenes y los recursos para desarrollar y probar algoritmos de imágenes médicas, las formas en que se pueden introducir sesgos (y potencialmente mitigar) en los modelos de imágenes médicas y lo que nos depara el futuro.
¿Qué impulsó la creación de MIDRC?
mg: El uso de big data se ha disparado en los últimos años. Pero el poder de los macrodatos sólo podrá aprovecharse plenamente una vez que los datos mismos hayan sido verificados y seleccionados. Tal como está el campo ahora, los datos de imágenes médicas utilizados para crear algoritmos clínicos pueden carecer de la calidad, cantidad y diversidad necesarias para desarrollar productos éticos y confiables. Los efectos posteriores de tales sistemas de inteligencia artificial podrían tener enormes ramificaciones, sometiendo a poblaciones subrepresentadas a daños potenciales y perpetuando las disparidades en el entorno médico.
A finales de 2019, NIBIB y sus colaboradores estaban buscando un caso de uso (un problema clínico específico, como cómo mejorar el diagnóstico de cáncer de mama utilizando imágenes de mamografía, por ejemplo) para encabezar el desarrollo de un repositorio sólido de imágenes médicas. Este depósito de datos necesitaría tener datos de imágenes diversos y seleccionados junto con resultados de pacientes a los que investigadores de todo el mundo pudieran acceder libremente para facilitar el desarrollo de algoritmos confiables de aprendizaje automático.
Y luego llegó la pandemia. Aparentemente de la noche a la mañana, tuvimos un caso de uso: una necesidad urgente de recopilar imágenes médicas y utilizar IA para predecir el diagnóstico, la gravedad y los resultados de COVID-19. Para ello, necesitábamos crear la infraestructura para recopilar, armonizar y almacenar enormes cantidades de imágenes, así como datos clínicos y demográficos asociados. Y así, en agosto de 2020, nació MIDRC.
Al momento de escribir este artículo, hemos recopilado imágenes de tórax (tanto radiografías como tomografías computarizadas) de casi 55,000 pacientes en todo Estados Unidos. Estas imágenes han ayudado a crear 27 algoritmos internos para la detección, diagnóstico, seguimiento y pronóstico de COVID-19.
¿Cómo facilita MIDRC el desarrollo de algoritmos?
mg: El primer paso para construir un buen algoritmo es encontrar buenos datos. Durante la pandemia, cuando la gente luchaba por desarrollar algoritmos, se extrajo información de todo tipo de fuentes, lo que dio lugar a conjuntos de datos que contenían imágenes de baja calidad, casos duplicados o grupos de pacientes que no eran representativos de la población general. Basura entra, basura sale: en el aprendizaje automático, no se puede tener un buen resultado si no se tiene una buena entrada.
MIDRC está trabajando para abordar este problema de múltiples maneras. Recopilamos datos de diagnóstico por imágenes de todo el país y los organizamos para que los investigadores puedan extraer fácilmente lo que necesitan para desarrollar un algoritmo de IA. Los algoritmos de imágenes médicas son muy específicos: abordan una pregunta clínica específica para una población específica. Un algoritmo puede afirmar, por ejemplo, que puede predecir la gravedad de la COVID-19 a partir de radiografías de tórax entre mujeres negras. La base de datos MIDRC permite a los investigadores extraer los datos específicos que necesitan para crear un algoritmo para su uso clínico específico.
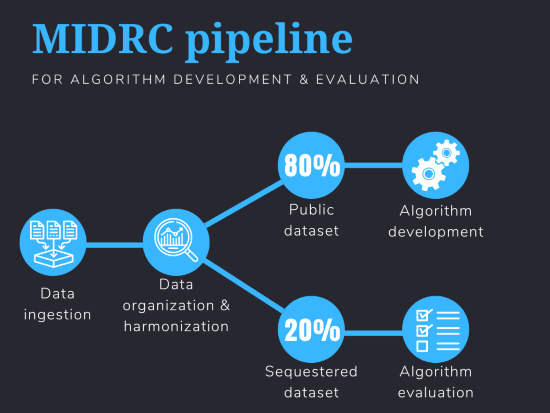
Más allá de proporcionar datos para el desarrollo de algoritmos, MIDRC también facilita la prueba y validación de algoritmos. Si bien aproximadamente el 80 % de los datos que ingerimos son de libre acceso para el público para uso en investigación, mantenemos el 20 % restante en un conjunto de datos separado y secuestrado. Este conjunto de datos secuestrados nunca se utilizará para el desarrollo de algoritmos, ya que solo se utilizará para probar algoritmos. Ahora que MIDRC está en su tercer año, nuestro conjunto de datos secuestrados es lo suficientemente grande como para comenzar a evaluar qué tan bien se está desempeñando un algoritmo determinado. Un investigador puede venir a MIDRC con un algoritmo que haya creado y nosotros podemos extraer la población deseada del conjunto de datos secuestrados y evaluar el algoritmo para ver si funciona como se anticipó. Acabamos de comenzar a trabajar con empresas para evaluar sus algoritmos y acelerar el proceso de recepción de la aprobación regulatoria de la FDA para uso clínico.
¿Cómo se puede introducir sesgos en los algoritmos de imágenes médicas?
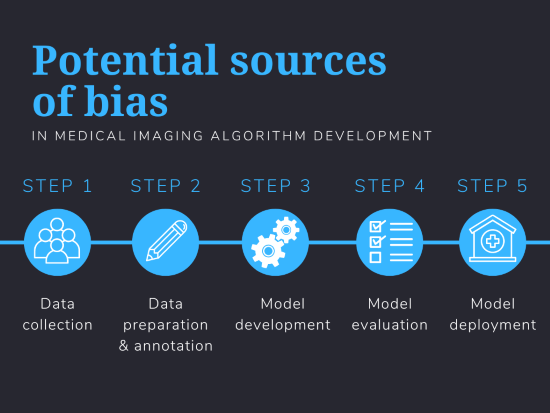
mg: Desafortunadamente, el sesgo puede colarse en un modelo de IA de muchas maneras diferentes. En nuestro reciente papeldescribimos alrededor de 30 factores distintos que pueden introducir sesgos en todo el proceso de aprendizaje automático. En resumen, se puede introducir sesgo en todos y cada uno de los pasos del proceso, desde los datos que se utilizan para desarrollar el algoritmo hasta cómo se prueba el modelo y, en última instancia, se implementa en la clínica. Un algoritmo que se desarrolló con una o más fuentes de sesgo podría, en última instancia, afectar la atención al paciente.
Algunas fuentes de sesgo parecen obvias. Es posible que un algoritmo desarrollado utilizando datos recopilados de pacientes blancos no funcione como se describe en un sistema hospitalario donde la mayoría de los pacientes son hispanos. No se debe esperar que los modelos que pueden predecir el pronóstico de COVID-19 a partir de radiografías de tórax predigan el pronóstico del cáncer de pulmón utilizando el mismo tipo de exploración. Y no se puede esperar que los algoritmos que utilizan imágenes de los mismos pacientes para desarrollar y probar el algoritmo sean generalizables y funcionen con precisión en múltiples poblaciones de pacientes.
Otras fuentes de sesgo son más sutiles. Un ejemplo es el sesgo temporal, donde los datos utilizados para desarrollar un modelo quedan obsoletos. Piense en los primeros días de la pandemia: cuando los pacientes ingresaban en el hospital, presentaban una enfermedad aguda y grave sin ninguna inmunidad previa. Hoy en día, si el mismo paciente contrajo COVID-19, probablemente haya recibido una vacuna o haya tenido un ataque previo de la enfermedad, y las características en sus radiografías de tórax pueden verse muy diferentes. Diferentes variantes a lo largo de la pandemia han dado lugar a diferentes presentaciones de la enfermedad. De esta manera, es posible que los datos adquiridos en 2020 ya no sean tan adecuados para el desarrollo de algoritmos COVID-19 como lo eran antes, y es probable que los algoritmos desarrollados hace varios años deban ser reevaluados para ver si todavía funcionan según lo previsto.
Afortunadamente, existen formas de mitigar los sesgos en los modelos de IA que se han desarrollado para analizar imágenes médicas. MIDRC ha creado un sitio en línea herramienta de concientización sobre prejuicios que describe fuentes potenciales de sesgo, cómo surgen estos sesgos y sugerencias sobre cómo corregirlos mejor. Esperamos que los investigadores utilicen esta herramienta para comprender mejor cómo se pueden introducir sesgos en sus procesos de desarrollo y tomar medidas para disminuir o eliminar sesgos en sus algoritmos.
¿Cuál es el futuro del MIDRC?
mg: El objetivo general de MIDRC es respaldar el ecosistema de IA de imágenes médicas. Hemos construido la infraestructura para albergar y organizar imágenes médicas, hemos recopilado una gran cantidad de datos de imágenes del mundo real y hemos realizado un esfuerzo concertado para educar a los usuarios sobre el desarrollo de algoritmos y posibles fuentes de sesgo. El próximo gran impulso es implementar el conjunto de datos secuestrados para permitir que los algoritmos superen el proceso de aprobación de la FDA.
A medida que continúa la pandemia, MIDRC ahora recopila datos de pacientes con COVID largo y está ampliando su interoperabilidad con varios otros depósitos de datos. Más allá de recopilar imágenes de rayos X y tomografías computarizadas del tórax, estamos comenzando a recopilar imágenes del cerebro y el corazón capturadas mediante modalidades de imágenes adicionales, como la ecografía y la resonancia magnética. Ahora que MIDRC está incorporando múltiples tipos de imágenes de múltiples regiones diferentes del cuerpo, estará preparado para abordar otras enfermedades y problemas clínicos más allá del COVID-19.
Aunque la pandemia fue el catalizador para construir y lanzar MIDRC, es más que un depósito de imágenes de COVID-19. Las colaboraciones y la infraestructura que se han establecido proporcionan una base sólida para la creación de más conjuntos de datos de imágenes médicas y el desarrollo de algoritmos de IA para todo tipo de casos de uso.
El fin de la pandemia de COVID-19 no significa el fin del potencial de MIDRC. Una vez construida la infraestructura, esto podría ser sólo el comienzo.
Recursos
¿Quieres saber más sobre MIDRC? Visita el Sitio web del MIDRC.
¿Quiere echar un vistazo a los datos de imágenes médicas de MIDRC? Mira el Datos comunes de MIDRC.
¿Eres un desarrollador de IA? Participa en MIDRC segundo gran desafío que busca algoritmos para predecir la gravedad del COVID-19 a partir de radiografías de tórax.
¿Se pregunta cuál es la mejor manera de evaluar el rendimiento de su algoritmo de imágenes médicas? Echa un vistazo a MIDRC recomendaciones de métricas de rendimiento.
¿Quiere aprender más sobre inteligencia artificial y aprendizaje automático? Aquí está la hoja informativa de NIBIB que brinda información general y ejemplos de investigaciones recientes en esta área.
Artículo de MIDRC citado en esta historia: Drukker K., Chen W., Gichoya J., Gruszauskas N., Kalpathy-Cramer J., Koyejo S., Myers K., Sá RC, Sahiner B., Whitney H., Zhang Z., Giger ML, Hacia la equidad en la inteligencia artificial para el análisis de imágenes médicas: identificación y mitigación de posibles sesgos en la hoja de ruta desde la recopilación de datos hasta la implementación del modelo, J. Med. Imagen. 10(6), 061104 (2023), doi: 10.1117/1.JMI.10.6.061104.
MIDRC cuenta con el respaldo de NIBIB según los contratos 75N92020C00008 y 75N92020C00021.


